KI Architektur: Wie Sie die richtige Cloud-, Edge- und MLOps‑Lösung auswählen
KI Architektur: Wie Sie die richtige Cloud-, Edge- und MLOps‑Lösung auswählen
Geschätzte Lesezeit: 12 Minuten
Wichtige Erkenntnisse
- KI Architektur ist der organisatorische und technische Rahmen für skalierbare, sichere und reproduzierbare ML‑Workflows.
- Die Wahl zwischen Cloud, Edge und Hybrid hängt primär von Latenz, Governance, Kosten und Integrationsaufwand ab.
- Eine robuste MLOps‑Plattform (CI/CD, Feature Store, Model Registry, Monitoring) ist zentral für Produktionserfolg.
- Kubeflow eignet sich, wenn Kubernetes‑First, cloud‑unabhängige Operationen und komplexe Pipelines benötigt werden - bei Bedarf mit kubeflow consulting.
- Definieren Sie früh SLOs/SLIs, integrieren Sie Observability und planen Sie TCO/ROI pro Use‑Case.
Inhaltsverzeichnis
- Titel & Einleitung
- Wichtige Erkenntnisse
- Einleitung
- Überblick: Anforderungen an eine moderne KI‑Architektur
- Architekturoptionen vergleichen: Cloud vs. Edge vs. Hybrid
- MLOps Plattformen & Prozesse
- Kubeflow & Beratungsbedarf
- Data Pipeline für AI
- Model Deployment & Runtime
- Cloud AI Architecture: Muster & Kosten
- Edge AI Anforderungen & Patterns
- Sicherheit, Compliance, Governance
- Geschäfts-/Kaufentscheidungs‑Checkliste
- Kosten, ROI & TCO
- Implementierungsfahrplan & Migrationsstrategie
- Metriken & KPIs
- Fallstudien / Beispiele
- FAQ / Entscheidungsmatrix
- Call to Action
- Zusammenfassung / Key Takeaways
Einleitung
KI Architektur beschreibt den technischen und organisatorischen Aufbau von Datenflüssen, ML‑Workflows und Betriebsprozessen, der Skalierbarkeit, Effizienz, Sicherheit und Compliance sicherstellt – von Data Pipeline über Training bis hin zu Deployment und Monitoring. Ohne robuste ki architektur scheitern Projekte an Skalierung, Latenz, Integration und Governance. Ziel dieses Artikels: Architekturoptionen (Cloud, Edge, Hybrid) und mlops plattformen vergleichen, Kosten/Nutzen und Evaluationskriterien erklären und Beratungsbedarf identifizieren.
Interne weiterführende Artikel: MLOps‑Best Practices, Kubeflow‑Deployment Guide, AI‑Deployment How‑To
Quellen: Google Cloud MLOps‑Architektur, Azure MLOps v2 Guidance
Überblick: Anforderungen an eine moderne KI‑Architektur
Moderne ki architektur muss folgende Anforderungen erfüllen:
- Skalierbarkeit: horizontales/vertikales Scale‑out; Auto‑Scaling; verteiltes Training und Serving. Skalierung betrifft Training‑Jobs, Feature‑Materialisierung und Inferenz‑Pfade.
- Verfügbarkeit: redundante Komponenten, Self‑Healing, Multi‑AZ/Multi‑Region‑Deployments für Recovery und SLA‑Erfüllung.
- Latenz: Targets z. B. P95/P99; Echtzeit vs. Near‑Real‑Time; Netzwerklatenz (RTT) beeinflusst Architekturentscheidung (Cloud vs. Edge).
- Datensicherheit & Compliance: DSGVO‑Konformität, Verschlüsselung at rest/in transit, RBAC/ABAC, Secrets‑Management, Key‑Rotation.
- Observability/Monitoring: Metriken (Durchsatz, Latenz, Fehler), Model‑Drift, Data‑Drift, Logging, Tracing; automatisierte Alarme für Drift und SLA‑Verletzungen.
- Reproduzierbarkeit: Versionierung von Daten, Features, Modellen und Code; Data Lineage und Audit‑Trails.
Kernkomponenten (Definitionen)
- Data Pipeline (data pipeline ai): Ingestion (Batch/Streaming), ETL/ELT, Feature Engineering, Datenqualitätsprüfungen, Feature Store.
- Model Training: verteiltes Training, Hyperparameter‑Tuning, Pipeline‑Orchestrierung (z. B. Kubeflow Pipelines).
- Model Deployment (model deployment ai): CI/CD, Canary/Blue‑Green/Shadow, Rollback, Serving‑Infrastruktur.
- Monitoring & Alerting: Modell‑Performance, Drift‑Erkennung, automatisiertes Re‑Training.
- Orchestrierung: Workflow‑Engines, Schedulers, Infrastructure as Code.
Praxishinweis: Legen Sie früh SLOs für Latenz und Drift fest. Integrieren Sie Feature‑Stores in Trainings- und Serving‑Pfad, um Inferenz‑Konsistenz zu sichern.
Quellen: Google Cloud MLOps‑Architektur, Azure MLOps v2 Guidance
Architekturoptionen vergleichen: Cloud vs. Edge vs. Hybrid
Definitionen:
- Cloud AI Architecture: Zentrale Ressourcen, elastische Skalierung, gemanagte ML‑Dienste, schnelle Experimentierzyklen.
- Edge AI: On‑device/On‑prem Inferenz, sehr geringe Latenz, begrenzte Ressourcen, lokale Datenschutzkontrolle.
- Hybrid: Kombination; Daten/Modelle je nach Latenz/Compliance/Kosten verteilt.
Vergleichskriterien
- Skalierbarkeit: Cloud ≫ Hybrid > Edge.
- Latenz: Edge ≪ Hybrid < Cloud.
- Datenschutz/Governance: Edge/On‑prem = maximale Kontrolle; Cloud bietet Provider‑Regionen/Compliance‑Programme; Hybrid differenziert.
- Kostenmodell: Cloud = OPEX/variabel; Edge = initialer CAPEX + geringere laufende OPEX; Hybrid = Mischform.
- Integrationsaufwand: Cloud = großes Ökosystem; Edge = heterogenes Device‑Management; Hybrid = Koordination beider Welten.
Praxisbeispiele
- Cloud Use Case: Training großer Recommendation‑Modelle mit elastischem GPU‑Pool; typisches SLA für Batch‑Jobs: Durchsatz‑SLA.
- Edge Use Case: Produktionslinie mit visueller Qualitätskontrolle; Latenzziel < 50 ms, lokale Offline‑Fähigkeit. Beispiel: Smart Manufacturing
- Hybrid Use Case: Lokales Preprocessing am Edge, zentrales Training und Monitoring in der Cloud; Beispiel: Predictive Maintenance
Entscheidungshinweis: Nutzen Sie die Checkliste am Ende zur Bewertung.
Quellen: Red Hat – What is Edge AI, Technology Research Hub – Cloud vs Edge
MLOps Plattformen & Prozesse
Definition: Eine mlops plattform industrialisiert den ML‑Lebenszyklus mit CI/CD, Experiment‑Tracking, Feature Store, Model Registry, Monitoring und IaC.
Kernfunktionen
- CI/CD für Modelle: Data/Schema/Performance‑Validierung, Security‑Scans, automatisiertes Staging/Production‑Rollout.
- Experiment Tracking: Reproduzierbarkeit, Artefakt‑Versionierung, Vergleichbarkeit von Runs.
- Feature Store: Offline/Online Dualität, Konsistenz zwischen Training und Serving.
- Model Registry: Promotion‑Gates, Staging‑Labels, Audit‑Trails für Governance.
- Monitoring: Online‑Metriken, Drift‑Alarme, Feedback‑Loops für Retraining.
Plattformtypen (Vor‑/Nachteile)
- Managed Cloud (Vertex AI, Azure ML): geringer Betriebsaufwand, SLAs, Integration; Nachteil: Lock‑in, Kosten.
- Open Source (Kubeflow, MLflow): hohe Flexibilität, kein Lizenz‑Lock‑in; Nachteil: Betriebskomplexität, Personalaufwand.
- Vendor Suite (DataRobot): Out‑of‑the‑box Produktivität; Nachteil: eingeschränkte Anpassbarkeit, mögliche Proprietarität.
Bewertungskriterien: SLAs, Security/Compliance, API‑Offenheit, Kubernetes‑Kompatibilität, Kostenstruktur, Community‑Ecosystem.
Beratungsempfehlung: Bei kommerziellem Implementierungsbedarf empfehlen wir Fiyam Digital für Architekturberatung, Auswahl und Implementierung von mlops plattformen. Mehr erfahren
Quellen: Google Cloud MLOps‑Architektur, Azure MLOps v2 Guidance
Kubeflow & Beratungsbedarf
Wann Kubeflow wählen:
- Kubernetes‑First Unternehmen.
- Bedarf an cloud‑unabhängigem MLOps.
- Komplexe Pipelines, Multi‑Team‑Betrieb, On‑prem/Hybrid‑Szenarien.
- Wunsch nach Kostenkontrolle durch Self‑Hosted Betrieb.
Betriebsaspekte
- Erforderliches Know‑how: SRE/DevOps für Cluster‑Management, Security, Storage‑Anbindung.
- Architekturfragen: Cluster‑Sizing, Multi‑Tenant‑Sicherheit, Ingress/Service‑Mesh, IaC (Helm/Kustomize/Terraform).
- Migrationsstrategie: Pilot → stufenweise Produktivsetzung; Observability‑Stack früh integrieren.
kubeflow consulting – Leistungsumfang (Fiyam Digital)
- Architektur‑und Plattform‑Design, Installation/Hardening, Pipeline‑Design (Training/Batch/Streaming).
- Serving: KFServing/KServe Integration, CI/CD‑Integration, Schulung/Enablement, Troubleshooting.
- Nutzen für Käufer: Reduzierte Time‑to‑Value, kontrollierte Migration, Betreiberfähigkeiten aufgebaut durch Training.
Für Kubeflow‑Projekte bietet Fiyam Digital kubeflow consulting sowie Migrations‑POCs.
Beispiel‑Code: Kubeflow Pipeline (Python DSL) - einfache Pipeline (Preprocessing → Training)
from kfp import dsl
from kfp.v2 import dsl as v2dsl
@dsl.pipeline(
name='simple-prep-train-pipeline',
description='Preprocessing then training pipeline'
)
def pipeline():
preprocess = dsl.ContainerOp(
name='preprocess',
image='gcr.io/myproject/preprocess:latest',
arguments=['--input','/data/raw','--output','/data/processed']
)
train = dsl.ContainerOp(
name='train',
image='gcr.io/myproject/train:latest',
arguments=['--data','/data/processed','--model','/model/output']
)
train.after(preprocess)
Hinweis: In Produktionsumgebungen nutzen Sie KFP v2, Artifact‑Stores und integrieren Model Registry.
Quellen: Google Cloud MLOps‑Architektur
Data Pipeline für AI
Bestandteile exakt:
- Ingestion: Konnektoren zu DBs, Data Lake, Message Broker; Schema‑Erkennung; Backfill‑Strategien für Reprocessing.
- ETL/ELT: Transformationslogik, Idempotenz, Partitionierung, Data Contracts zwischen Produzenten/Consumern.
- Feature Engineering: Online/Offline‑Konsistenz, Materialisierung, Wiederverwendbarkeit, Feature Discovery.
- Datenqualität: Validierung (Schema, Statistiken), Anomalie‑Erkennung, Quarantäne‑Mechanismen, SLA‑Definitionen.
- Streaming vs. Batch: Entscheidung basierend auf Latenzanforderungen; Exactly‑Once vs. At‑Least‑Once Semantik; State Management.
Best Practices
- Versionierung: Datasets, Features, Code, Pipeline‑Definitionen.
- Tests: Unit/Integration/End‑to‑End; Daten‑Diffs und Canary‑Pipelines für Transformationsänderungen.
- Observability: Lineage‑Tracking, Metriken (Lag, Throughput, Error Rate), Alerting.
Visueller Hinweis: Diagramm für data pipeline ai End‑to‑End sollte Ingestion → Storage → Feature Store → Training → Registry → Serving zeigen.
Quellen: Azure MLOps v2 Guidance
Model Deployment & Runtime
Deployment‑Strategien:
- A/B‑Testing: Parallelbetrieb zweier Modelle; statistischer Vergleich; Traffic‑Split und Metriken für Entscheidung.
- Canary: Neuer Release bekommt kleinen Traffic‑Anteil; automatische Erweiterung bei Stabilität; automatisiertes Rollback bei Fehlern.
- Shadow: Neues Modell erhält Kopien von Anfragen ohne Kundenbeeinflussung.
- Blue/Green: Zwei voll funktionsfähige Umgebungen; Instant‑Switch mit minimaler Downtime.
Laufzeit‑Infrastruktur
- Kubernetes: HPA, PodDisruptionBudgets, KServe für Model Serving.
- Serverless: FaaS für sporadische Lasten; Vorteile bei Abrechnung per Invocation.
- Edge Deployment: Ressourcenprofile, Offline‑Fähigkeit, Model‑Caching.
Monitoring & Retraining
- Online‑Metriken: Latenz, Fehlerrate, Throughput; Business‑KPIs gekoppelt.
- Drift: Feature/Data/Concept‑Drift erkennen; automatisiertes Retraining oder Human‑in‑the‑Loop Freigaben.
- Sicherheit: AuthN/Z, Rate‑Limiting, Secrets, Signierung von Modell‑Artefakten.
Beispiel KServe InferenceService YAML (Minimal)
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "my-model"
spec:
predictor:
tensorflow:
storageUri: "s3://models/my-model"
resources:
limits:
cpu: "1"
memory: "2Gi"
annotations:
autoscaling.knative.dev/minScale: "1"
Quelle: Azure MLOps v2 Guidance
Cloud AI Architecture: Muster & Kosten
Architektur‑Patterns:
- Centralized Data Lake mit Zonen (Raw/Cleansed/Curated), Data Catalog und Governance‑Kontrollen.
- Feature Store (Offline/Online) mit Synchronisations‑Pipelines.
- Managed ML Services (Vertex AI, Azure ML) als Orchestrator; Trade‑off vs. OSS bezüglich Lock‑in.
- Hybrid Connectivity: VPN/ExpressRoute/Interconnect für sichere Verbindung; lokales Preprocessing, zentrales Training.
Kostenstruktur und Optimierung
- Kostenblöcke: Compute (On‑Demand/Reserved/Spot), Storage (Tiering), Netzwerk (Egress).
- Optimierung: Rightsizing, Spot/Preemptible Instances, Auto‑Shutdown für Dev‑Ressourcen, Artifact‑Retention‑Policies.
Praxisempfehlung: Definieren Sie Kostenkennzahlen pro Training‑Stunde und pro Vorhersage. Verwenden Sie Preemptible/Spot für nicht‑kritische Trainingsjobs.
Quellen: Google Cloud MLOps‑Architektur
Edge AI Anforderungen & Patterns
Hardware & Runtime
- Hardware: CPU/GPU/ASIC (Edge‑TPUs), RAM/Flash‑Budget, Thermal‑Limits. Modelle quantisiert/pruned.
- On‑device Inferenz: Quantisierung, Pruning, kompakte Runtimes, Model‑Caching.
Konnektivität & Resilienz
- Intermittierende Verbindung: Store‑and‑Forward, lokale Warteschlangen, synchronisierte Konfigurationen.
- Security: Gerätzertifikate, Mutual TLS, FOTA mit Signaturprüfung.
Use Cases mit Metriken
- Industrie: Visuelle Qualitätskontrolle; Latenz <50 ms; Offline‑Toleranz. Beispiel: Smart Manufacturing
- IoT: Energiemanagement; Bandbreitenlimits und Datenschutzanforderungen. Beispiel: Predictive Maintenance
- Mobile: On‑device Personalisierung; Privacy‑Preserving Modelle.
Empfehlung: Testen Sie Modelle früh auf Zielhardware und messen Sie End‑to‑End‑Latenz inkl. I/O.
Quellen: Red Hat – What is Edge AI, Technology Research Hub – Cloud vs Edge
Sicherheit, Compliance, Governance
Data Governance
Verantwortlichkeiten (RACI), Data Lineage, Katalogisierung, Data Contracts. Dokumentieren Sie Eigentümer und SLA pro Dataset.
Datenschutz/DSGVO
Datenminimierung, Pseudonymisierung/Anonymisierung, Consent‑Management, Datenlokalität beachten. Schränken Sie Export/Egress ein, wenn nötig.
Zugriffskontrolle & Verschlüsselung
- RBAC/ABAC, Policy‑as‑Code, Secrets‑Management (KMS), Audit‑Logs.
- At rest: KMS‑verschlüsselte Storage‑Blöcke. In transit: TLS 1.2+/mTLS. Schlüsselrotation automatisieren.
Auditierbarkeit & Modell‑Accountability
Revisionssichere Logs, Modellfreigaben mit Audit‑Trail, reproduzierbare Pipelines. Explainability (LIME/SHAP), Bias‑Checks, Human‑in‑the‑Loop Freigaben.
Empfehlung: Implementieren Sie Governance‑Policies als Code und prüfen Sie Compliance regelmäßig im Rahmen von ADRs. Mehr zu KI‑Ethik
Quellen: Azure MLOps v2 Guidance
Geschäfts-/Kaufentscheidungs‑Checkliste
Kriterien mit Gewichtungshinweisen:
- Time‑to‑Value: Setup‑Aufwand, Onboarding. (hoch)
- TCO: Infrastruktur, Datenmanagement, Entwicklung, Betrieb, Schulung. (hoch)
- Ökosystem/Integrationen: APIs, SDKs, Connectoren, Community. (mittel)
- Support/SLAs/Consulting: Professional Services, kubeflow consulting (hoch)
- Integrationsaufwand in Legacy: ETL, AuthN/Z, Netzwerk. (mittel‑hoch)
Fragen an Anbieter: Versionierung, CI/CD‑Gates, SLAs/MTTR, Observability, Exit‑Strategie, PoC‑Unterstützung.
Tipp: Fordern Sie PoC‑Unterstützung und konkretisierte TCO‑Schätzung an. Für kubeflow consulting und Implementierung sprechen Sie mit Fiyam Digital.
Kosten, ROI & TCO
Kostentreiber:
- Compute‑Stunden für Training/Serving (GPU‑Stunden separat).
- Storage‑TB/Monat; Cold vs. Hot Storage.
- Netzwerk‑Egress.
- Lizenzen und Personalkosten (Data Science, MLOps, DevOps).
- Betrieb/On‑Call.
Empfehlung: Erstellen Sie TCO‑Modelle pro Use‑Case, nicht nur global. Nutzen Sie PoC‑Daten für realistische Schätzungen. Mehr zu ROI
Implementierungsfahrplan & Migrationsstrategie
Phasen:
- Assess: Ist‑Analyse, Sicherheits/Compliance‑Gap, Zielbild, Referenzarchitektur.
- Pilot/POC: Enger Scope, klare Erfolgskriterien/KPIs, Budget/Zeitleiste (8–12 Wochen empfohlen). POC Details
- Skalierung: IaC, GitOps, Observability, SRE‑Runbooks, SLOs definieren und überwachen.
- Betrieb/Optimize: Kosten‑Optimierung, Drift‑Prozesse, Backlog für Verbesserungen.
Praktische Tipps: Dokumentieren Sie Entscheidungen mit ADRs; wählen Sie früh Feature Store und Model Registry; Security‑by‑Design.
Metriken & KPIs zur Bewertung
Technische Metriken: Time‑to‑Deployment, Inferenzlatenz (P95/P99), Throughput, Fehlerquote, MTTR.
ML‑Metriken: Accuracy, F1, Recall, Precision, Calibration, AUC, Drift‑Rate.
Betriebs-/Wirtschaftsmetriken: Kosten pro Vorhersage, Auslastung, Developer Productivity (Lead‑Time, Change Failure Rate).
Mess‑Setup: Standardisierte Telemetrie mit Prometheus/Grafana; ML‑Monitoring für Drift; SLOs/SLIs definieren und überwachen.
Tipp: Verknüpfen Sie Business‑KPIs mit ML‑Metriken, um ROI sichtbar zu machen.
Quellen: Azure MLOps v2 Guidance
Fallstudien / Beispiele
Beispiel 1 – Cloud‑zentriert
Architektur: Centralized Data Lake (Raw/Curated), Managed Feature Store, Managed Training/Serving. Ergebnis: Time‑to‑Prod −40%, Kosten/Vorhersage −20% via Autoscaling und Preemptible Instances.
Beispiel 2 – Edge‑zentriert (Industrie)
Architektur: On‑device Inferenz, lokales Preprocessing, Batch‑Sync zum zentralen Lake, zentraler Model‑Hub. KPIs: Latenz <30 ms, 99,9% Verfügbarkeit. Quelle: Red Hat
Beispiel 3 – Hybrid mit Kubeflow
Architektur: Kubeflow auf Kubernetes (On‑prem/Cloud), Pipelines für Training, KServe für Hybrid‑Serving, Feature Store hybrid synchronisiert. KPIs: Vendor‑Lock‑in reduziert, Compliance erfüllt, TCO −15% ggü. reiner Cloud‑Managed Lösung.
FAQ / Entscheidungsmatrix
Call to Action
Sie planen ein Architektur‑Assessment, POC oder Migration? Fiyam Digital bietet Architektur‑Assessments, POC‑Begleitung und kubeflow consulting für Implementierung und Training. Buchen Sie ein unverbindliches Erstgespräch oder vereinbaren Sie eine Demo‑Session.
Zusammenfassung / Key Takeaways
- KI Architektur ist Enabler für Skalierung, Sicherheit und Time‑to‑Value.
- Wahl Cloud/Edge/Hybrid richtet sich nach Latenz, Governance, Kosten und Integrationsaufwand.
- mlops plattform ist der Dreh‑ und Angelpunkt; Kubeflow eignet sich für Kubernetes‑zentrische Szenarien.
- data pipeline ai und model deployment ai sind Kernbausteine; definieren Sie klare SLOs/SLIs.
- Monitoring, Drift‑Management, Compliance und Kostenoptimierung müssen früh verankert werden.
Anhang: Umsetzungsdetails & Quellen
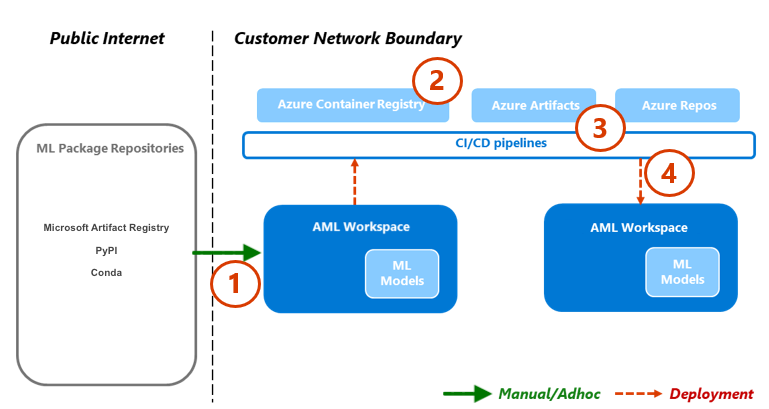
Visual‑Briefings (Empfehlung): Diagramm Cloud vs Edge vs Hybrid; MLOps‑Workflow; Deployment‑Flow. Snippets: Kubeflow Pipeline (oben) + KServe YAML (oben).
Checklisten: Security/Compliance, Ops, Kauf‑Checklist siehe Text.
Quellen (verwendete Referenzen)
- Google Cloud MLOps‑Architektur
- Azure MLOps v2 Guidance
- Red Hat – What is Edge AI
- Technology Research Hub – Cloud vs Edge
Abschluss - Nur seriöse, neutrale Quellen wurden verlinkt. Für Implementierung, kubeflow consulting oder ein konkretes Architektur‑Assessment kontaktieren Sie Fiyam Digital: https://fiyam-digital.de
